OpenAI Deep Research API and Webhooks
OpenAI’s Deep Research has quickly emerged as one of the most powerful tools released this year, delivering high-quality, structured analysis across a wide range of topics. In a previous video, I explored its performance in dissecting the endpoint security market. The results were impressive, handily outperforming comparable outputs from Google Gemini.
But for all its strengths, the original Deep Research tool came with some clear limitations. It wasn’t easy to integrate into your own apps or workflows, and it didn’t support analysis of private documents and research.
That’s where OpenAI’s new Deep Research API comes in. This API unlocks developer access to everything that makes Deep Research powerful, allowing you to initiate research programmatically, blend in your private data via an MCP server, and deeply integrate the outputs into your own systems.
In this tutorial, we’ll walk through the architecture and implementation of a simple end-to-end application that:
- Provides a UI for managing Deep Research prompts
- Triggers Deep Research agents that can search the web and write reports on demand or on a schedule
- Handles incoming reports via webhooks, processes them, and stores them in a local database
- Displays the full reports in a clean, custom web interface
- Generates PDF's of these reports with your own logo and sends branded emails
- Ingests premium subscription content (eg. Stratechery) into OpenAI’s Vector Store
- Makes this content searchable by Deep Research using an MCP Server
Deep Research API
Programmatically kicking off a Deep Research task is as simple as calling the OpenAI Responses API and using a Deep Research reasoning model (eg. o3-deep-research or o4-mini-deep-research). Your API request must also specify one or more tools for the deep research agent to use. For example, you probably want to use the "web_search_preview" tool to get the latest content from the web. If you want it to perform calculations and generate charts and graphs, you can also specify that you want it to use the code interpreter. If you want to provide some private data, you can expose it to Deep Research via an MCP server tool. More on that later.
The code below comes directly from the OpenAI Cookbook, but I've added prompts that are specific to researching the company ServiceNow. I've also shared the code in a Google Colab notebook here.
import os
from google.colab import userdata
from openai import OpenAI
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
client = OpenAI(timeout=3600)
system_message = """
You are a senior research analyst specializing in the IT services sector. Your role is to generate detailed, structured, and data-driven research reports on companies and trends across areas such as endpoint security, remote monitoring and management (RMM), helpdesk/ticketing platforms, and broader cybersecurity infrastructure.
Your reports must:
- Prioritize analyst-grade data: include concrete metrics such as ARR, YoY growth, NRR, customer count, pricing tiers, win rates, churn, gross margin, sales efficiency, and competitive positioning.
- Identify market dynamics: highlight adoption trends, regulatory headwinds/tailwinds, buyer personas, procurement cycles, and TAM/SAM/SOM breakdowns where relevant.
- Call out opportunities for visual summaries: e.g., “This competitive positioning would be well illustrated in a quadrant chart comparing NRR vs. growth rate.”
- Source only credible, recent material: prioritize earnings calls, investor presentations, SEC filings, reputable industry reports (e.g., Gartner, IDC, Forrester), and coverage from top-tier financial media or equity analysts.
- Include inline citations and return full source metadata (document name, company, date, source, and link if available).
Maintain an analytical tone—avoid generalities or fluff. Every insight should be grounded in data and suitable for informing investment theses, strategic planning, or competitive intelligence.
"""
prompt = """
Research **ServiceNow (NYSE: NOW)** as an investment and strategic competitive intelligence target within the IT services sector. Produce a detailed, structured report covering the following areas:
1. **Company Overview**
* Core products and services (with emphasis on ticketing, workflow automation, ITSM, and security operations)
* Key customer segments and industries served
* Recent product launches or platform expansions
2. **Financial Performance (Last 3 Years + Latest Quarter)**
* Revenue, ARR, YoY growth, gross margin, operating margin, NRR, free cash flow
* Segment breakdowns (e.g., by product line or geography if available)
* Commentary from earnings calls or investor presentations
3. **Go-to-Market and Sales Efficiency**
* Sales motion (enterprise direct vs. channel)
* Average contract value, customer count, churn or retention data
* Sales efficiency metrics if available (e.g., CAC payback, Magic Number)
4. **Competitive Landscape**
* Key competitors (e.g., Atlassian, Freshworks, Zendesk, BMC)
* Differentiators and weaknesses
* Analyst quadrant positioning (e.g., Gartner Magic Quadrant, Forrester Wave)
5. **Strategic Risks and Opportunities**
* Emerging threats (AI-first competitors, market saturation, pricing pressure)
* Areas of growth (workflow automation, security integration, AI copilots)
* M&A activity or targets
6. **Valuation and Market Sentiment**
* Current valuation multiples (EV/Revenue, EV/EBITDA, P/E)
* Analyst consensus and institutional ownership trends
* Notable hedge fund or activist positions if relevant
When possible, summarize quantitative data in formats that could be turned into charts or tables. Cite all sources with full metadata (title, author/org, publication date, and link).
The tone should be analytical and precise—suitable for an investor or strategic operator evaluating ServiceNow in the context of the IT services sector.
"""
response = client.responses.create(
model="o4-mini-deep-research-2025-06-26", # or o3-deep-research for more detail at a higher cost
input=[
{
"role": "developer",
"content": [
{
"type": "input_text",
"text": system_message,
}
]
},
{
"role": "user",
"content": [
{
"type": "input_text",
"text": prompt,
}
]
}
],
background=True,
tools=[
{"type": "web_search_preview"}
],
)
You'll notice that we kicked this off with background=True, meaning that the agent will run in the background and the next line of code will continue executing before the response is finished.
So how do we know when our deep research task is done? Well the documentation mentions that we can poll until it is complete like so:
import time
while response.status in {"queued", "in_progress"}:
print(f"Current status: {response.status}")
time.sleep(5)
final_response = client.responses.retrieve(response.id)
print(f"Final status: {final_response.status}\nOutput:\n{final_response.output_text}")However, my findings so far were that the status was showing "queued" even after the response had already been generated. I have found it more helpful so far to go directly to the logs in the OpenAI Platform. From here, we can see the complete details of a particular API call, including a timestamp, model and tools used, token count, reasoning steps, and final output.
How much does it cost?
Speaking of token count, be sure to check the latest pricing for the model you are using. While these costs continue to go down over time, using Deep Research and reasoning models can be quite costly. My runs of the o4-mini-deep-research model were around $1-3 per API call. While this may seem expensive, recall that when I first made videos on GPT-3 and GPT-4 it cost as much just for a simple text completion. Now we're getting full web searches and high quality research reports. For use cases like investing and coding, these costs are trivial since you should be able to generate far more revenue if these tools significantly boost your productivity.
Webhooks
Obviously you don't want to check your OpenAI logs every time you want to see a Deep Research report. You also may want to do additional processing on a Deep Research report. For instance, you may want to store the output in a database or generate tags and extract topics from the report. This is where webhooks are extremely handy. Webhooks provide a way for an application to call you back when an event of interest actually happens. In our case, we want OpenAI to call us back when a new Deep Research response has completed.
The OpenAI settings page provides an interface for configuring webhooks:
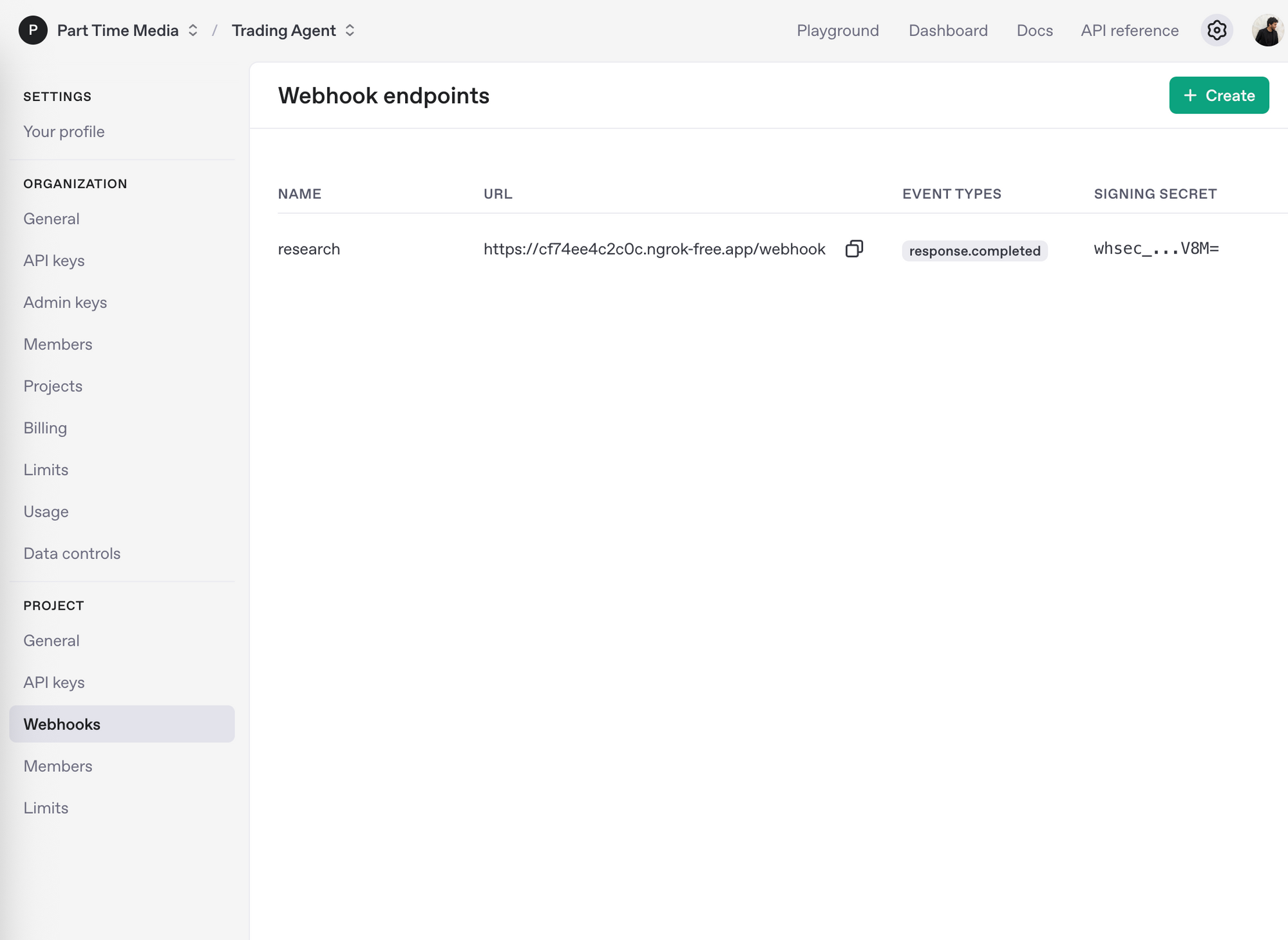
To define a new webhook endpoint, you simple click the Create button and enter a URL for OpenAI to POST to when a given event occurs. In our case, we are interested in when a response is completed, so we select the response.completed event type in the form:
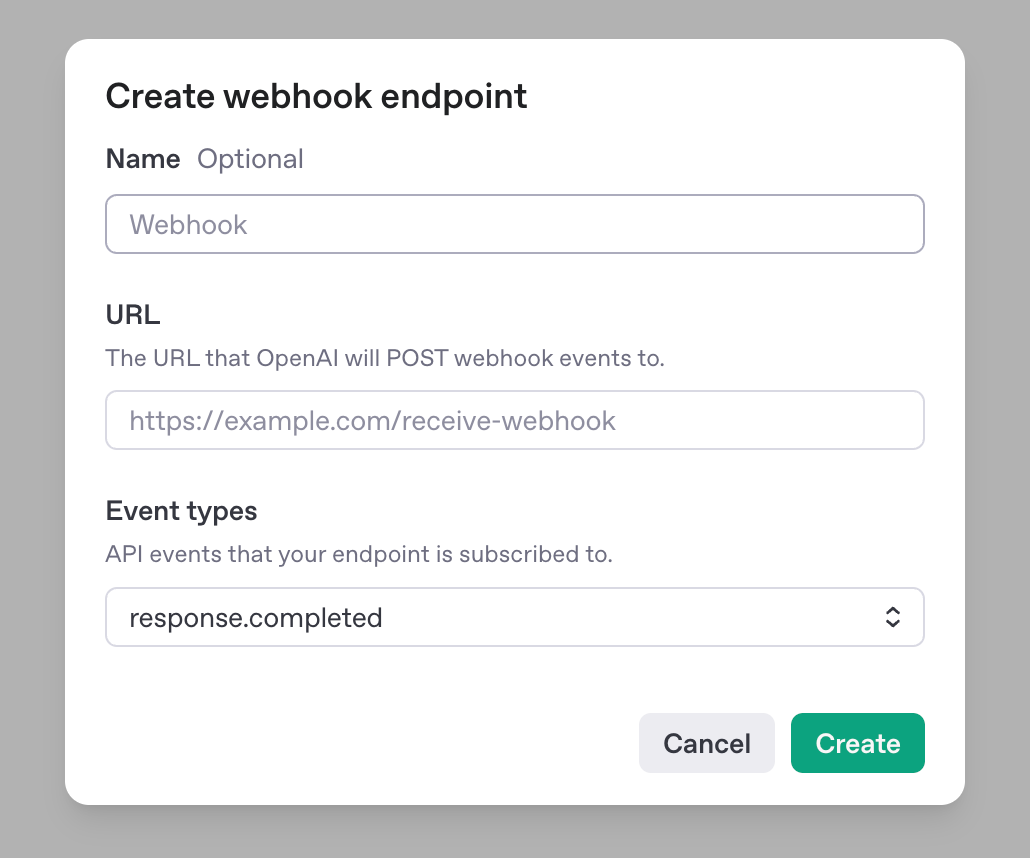
This endpoint is where we will implement any special processing code we want to execute when a Deep Research task completes. But we don't have and endpoint yet, so we need to code it!
Coding the endpoint
The example provided by OpenAI is a simple Flask route. I decided to expand upon and have the webhook do the following:
- Store each research report in my database
- Extract the topic and primary company associated with each report
- Put my special Part Time Research logo on each report
- Send an email with my research to all of my clients in PDF form
Database Storage
First, I wanted to store the data inside of a table called research. This lets me build a simple web frontend to view these reports. I created a few tables:
- A table named "research" with the full output and the associated topic and primary company
- A "users" table for user authentication
- A "prompts" table to store commonly used prompts.
Here is the function from my app that executes the SQL to create the tables:
def create_tables():
conn = get_db()
conn.execute("""
CREATE TABLE IF NOT EXISTS research (
id INTEGER PRIMARY KEY AUTOINCREMENT,
response_id TEXT,
prompt TEXT,
output TEXT,
company TEXT,
topic TEXT,
pdf_path TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
conn.execute("""
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT UNIQUE NOT NULL,
email TEXT UNIQUE NOT NULL,
password_hash TEXT NOT NULL,
is_admin BOOLEAN DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
conn.execute("""
CREATE TABLE IF NOT EXISTS prompts (
id INTEGER PRIMARY KEY AUTOINCREMENT,
topic TEXT NOT NULL,
text_prompt TEXT NOT NULL,
model TEXT NOT NULL DEFAULT 'gpt-4o-mini',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
conn.commit()
conn.close()Webhook Endpoint and Structured Extraction
Now that we have a place to store the data, let's create a /webhook endpoint that can accept the OpenAI webhook payload. How do we know who is posting to our webhook? We don't want anyone on the internet to be able to post data to our system. The good news is that OpenAI provides a special webhook secret when you register a webhook. This authenticates the webhook request and allows us to verify that the request is from OpenAI with a single line of code:
event = client.webhooks.unwrap(request.data, request.headers)
Once we have verified the webhook request, we will do some structured extraction on the report using a model like gpt-4o and store the result in our database tables. I have already covered Structured Output in one of my GPT4-o videos, so I assume you already have some familiarity with this concept. We define a Pydantic model that represents the structure of the data we want to extract from the report's content:
class ResearchExtraction(BaseModel):
companies: List[str]
topics: List[str]
primary_company: str
primary_topic: strThen in our webhook we make a call to gpt-4o to extract the structured output and use a SQL INSERT to store the results in our database table.
@app.route("/webhook", methods=["POST"])
def webhook():
print("webhook called")
try:
print("request.data", request.data)
print("request.headers", request.headers)
event = client.webhooks.unwrap(request.data, request.headers)
if event.type == "response.completed":
response_id = event.data.id
response = client.responses.retrieve(response_id)
print("--------------------------------")
print("Response prompt:", response.prompt)
print("--------------------------------")
print("Response output:", response.output_text)
conn = get_db()
# Use OpenAI's structured output to extract companies and topics from the prompt
company = "Unknown"
topic = "General"
try:
print("Extracting structured data")
extraction_response = client.responses.parse(
model="gpt-4o",
input=[
{"role": "system", "content": "Extract the primary company and topic from this research prompt. Focus on the main company being analyzed and the primary topic/theme of the research."},
{"role": "user", "content": response.output_text}
],
text_format=ResearchExtraction,
)
print("Extraction response:", extraction_response)
extracted_data = extraction_response.output_parsed
company = extracted_data.primary_company if extracted_data.primary_company else "Unknown"
topic = extracted_data.primary_topic if extracted_data.primary_topic else "General"
print(f"Extracted - Company: {company}, Topic: {topic}")
except Exception as e:
print(f"Could not extract structured data: {e}")
company = "Unknown"
topic = "General"
# Generate PDF from the markdown output
pdf_path = generate_pdf_from_markdown(response.output_text, response_id, company, topic)
conn.execute("INSERT INTO research (response_id, prompt, output, company, topic, pdf_path) VALUES (?, ?, ?, ?, ?, ?)",
(response_id, response.prompt, response.output_text, company, topic, pdf_path))
conn.commit()
conn.close()
return Response(status=200)
except InvalidWebhookSignatureError as e:
print("Invalid signature", e)
return Response("Invalid signature", status=400)Hosting the Webhook
Currently we are just in development, so the Flask app is running on our desktop. How do we test that it works without deploying everything to a server? One option that is suggested by OpenAI is ngrok, which I covered in one of my old TradingView webhooks videos. If you haven't used it before, ngrok creates a secure tunnel from a public endpoint to your locally running webapp. To use it, simply install ngrok and run it on the command line with the port you are running your Flask app on. For instance, if you are running Flask on port 5001, you would run the following command:
ngrok http 5001It will give you a public endpoint that you can use when creating your OpenAI webhook. This way, OpenAI has a URL it can post to, and the payload will get routed to your local development machine. Obviously when you actually deploy this, you will change the URL to your production endpoint.
If you don't want to use ngrok, there are plenty of other alternatives, including:
- Cloudflare Tunnels
- Deploying your app to a VPS such as Linode or Digital Ocean
- Replit
- AWS Lambda
- Google Cloud Functions
Testing your webhook
I suggest using a regular cheap (non-deep research) model to test your webhook. First because the deep research models can be very expensive. And second, because they take a long time to finish. You may want to test your webhook quickly and cheaply before testing it with deep research. For example, I created a test_webhook.py that looks like this:
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI()
resp = client.responses.create(
model="gpt-4o",
input="Why should I care about Cloudflare as an investor? Focus on AI features like Cloudflare Workers AI, Cloudflare Containers, and AI Scraping.",
background=True,
tools=[ { "type": "web_search_preview" } ]
)
print(resp.status)This lets me test that OpenAI receives my request, calls my webhook back fairly quickly, my webapp correctly processes it without errors, and I can see my results in the dashboard. Once this is done, I feel more comfortable calling this with a larger, more expensive model.
Wrapping Up
There are many other possibilities you can add once you have such an integration working. For instance, I created a web UI for prompt storage, a function for sending branded emails, and a function for generating PDF's. Since this isn't a full stack web application development tutorial, we won't go into detail on these features. However, the implementation of these features is straightforward and you can reach out to me if your organization needs help implementing such things.